

导语:随着云存储业务蓬勃发展,节点数不断扩展。在数十万节点的庞大系统中,如何做到一周内完成全区域覆盖,并杜绝版本发布中的人为失误?文章围绕对象存储(以下简称COS)整体的发布演进,从发布效率的极致提升,平台发布标准化外包化上展开,讲解COS发布成熟度如何提升(当前level2+),希望提供业务通用的高质量变更模式与提效参考。
现网发布变更对运维来说,是最繁重的工作之一。发布变更的概念,节奏等已经是老生常谈。但在ToB时代到来后,云上业务的诉求,是功能/缺陷修复尽快上线,版本发出问题快速回退,防止客户业务受损。
在整个需求上线环节中,CD部分由运维实施,如何让版本更快的交付上线是我们核心的任务。

站长素材网近几年开始大力发展,对象存储COS架构也经历了一次存储引擎升级YottaStore的大迭代。随着公司自研上云的推广,2022年微信第一次在COS上过春保,稳定的服务得到了两个BG的点赞。
对象存储COS从用户接入到数据落地,要经历三个核心子平台:逻辑接入层、索引存储层、数据存储层。每个子平台内部还有数十个模块相互配合提供服务,任何一个链路出现异常都可能对数据PUT、GET、LIST、HEAD等接口造成可用性影响,COS节点数更是突破了10W+。
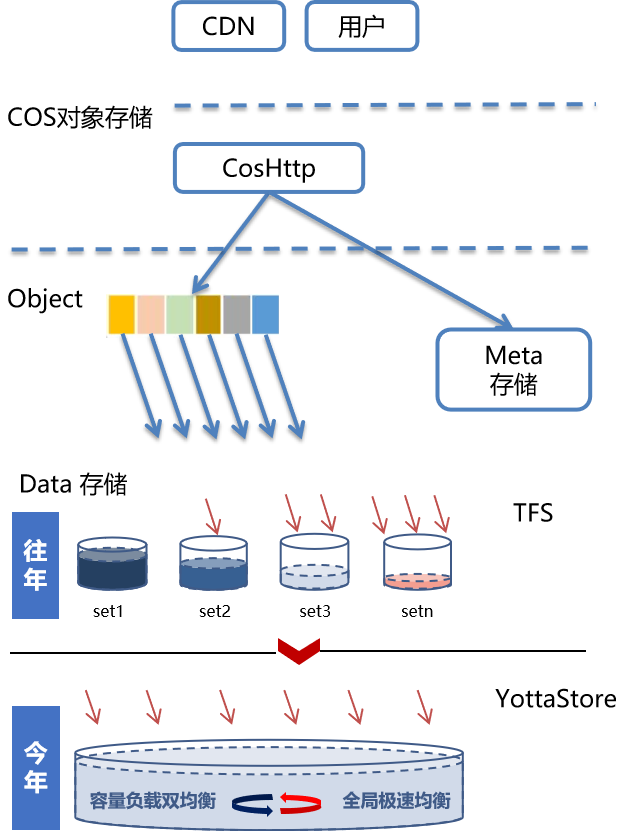
历史的存储引擎(TFS、LAVADB等),在变更中需要小set内串行,或将数据迁走然后变更。这类变更耗时是显而易见的(并且从耗时过长,就会引发意想不到的变更方式:按照版本组合来变更,按照各区域版本自治完全没有统一概念等),这类型的变更,最多做到流程标准化,可以set之间并发,或批量迁走数据再变更,但不解决本质问题。
YottaStore比传统TFS模式或LAVADB模式好的点就在于将小set模式的变更方式升级为集群百分比变更,打破理解set变更的模式,每个节点剔除加回也不需要等待数据迁移,本质性提高了存储变更效率上限。
YottaStore在上线的时候就对节点标签引入了MZ(Management Zone)的概念:同集群内跨MZ不能同时变更,减小误操作爆炸半径。例如,模块上线后使用20个MZ,跨MZ屏蔽节点会失败(保障现网最大5%的机器可以并发变更),当然在更核心服务配置时MZ应该设置的更多。
基于区域MZ适配发布优化策略,主要是通过COS对MZ编排做了适配,同时智研平台把并发度支持从100并发调整到500并发,同时对于单机模板执行效率也做了优化,整体优化了平台并发能力和发布流转效率,全园区覆盖效率提升100%。
为降低人工check等待时间,COS在单机变更模版引入变更的自检过程。

变更系统提供人工控制入口,对部署编排中的所有任务可以人工确认后直接启动,速度直线提升。
COS发布分离线计算,自研云集群,公有云海外,公有云国内(每个云属性下有多个集群),同云属性集群可以在灰度健康的情况下开启并发。正常的版本发布耗时大约在1周工作日内完成。
将发布流程放大,将每一环可能产生的问题明确。可以看到不必要的浪费和可节约的时间。
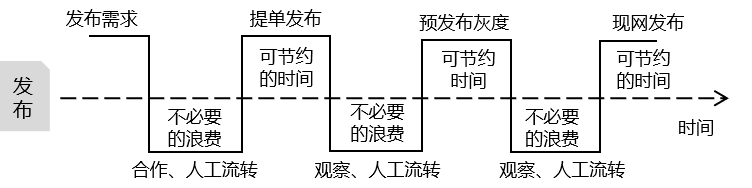
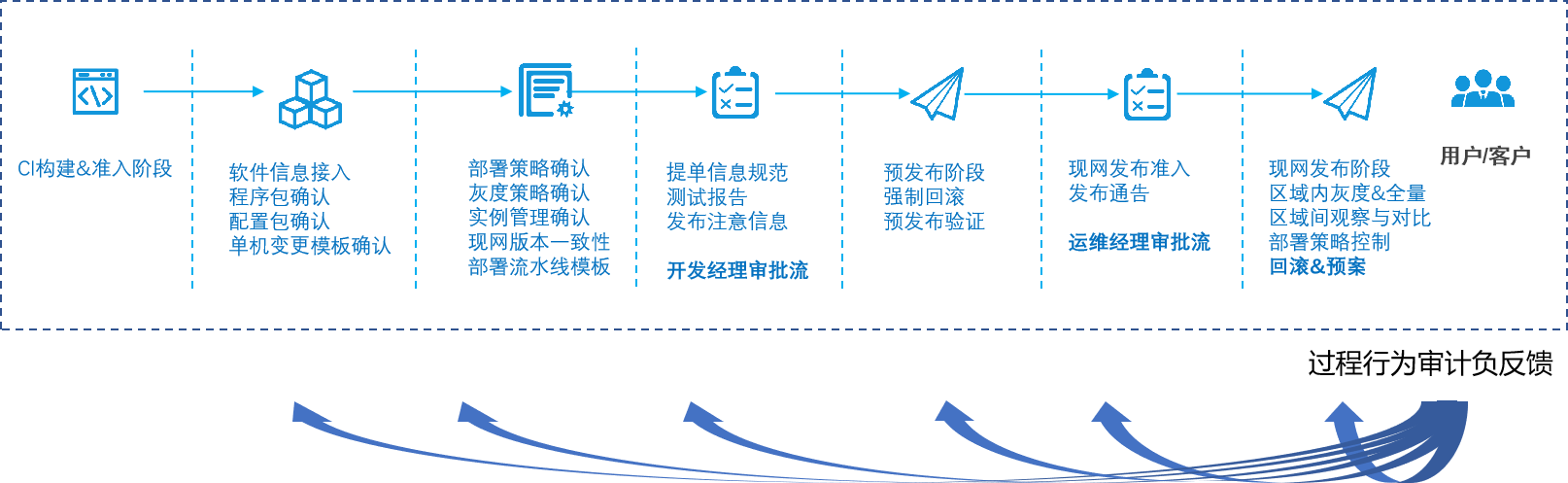
COS当前采用研发提单(仅提供提单权限),系统群内推送给到开发leader审批,预发布环境发布,再到运维leader审批现网发布的方式。其中流转通过自动群推送的方式减少人频繁@时间,与知会时间。
现网发布时,由于云上是区分客户等级的,所以在发布区域上用唯一流水线固化发布顺序来降低区域选择和流转时间。(流水线覆盖权限,且支持发布中临时调整)。其实固化对于质量的提升更多,后面来说。

发布流程优化图
上述点优化后,变更耗时从15天变更1w+设备,到4天变更4W+设备。那么,还有吗?
某次大规模故障复盘当晚,我们对于快速故障处理时的发布提出了挑战:回滚或者紧急的发布,能否在更快就支持完成?软件发布是否还有提效的空间?
答案是肯定的。
从细节出发,对于每一次单机变更做了记录,发现关键软件由于程序包太大,下载耗时就占了40%。该下发方案是,多台机器同时从变更系统拉取程序包,这使我们一下子就联想到了客户集中下载COS单对象的场景,该场景最优的解决方案,就是引入CDN的特性与优势:预热!
联合智研平台详细讨论变更效率和优化点,决定要上线软件包预热功能。在实现上,我们用了两种方案:
(1)缓存接入点就近分发:机器触发新包拉取的时候存一份到缓存接入点,后续机器拉包就去到就进的缓存接入点拉取,减少拉包时间。(缺点:需要尽可能多的缓存接入点,且COS地域较多,会耗成本)
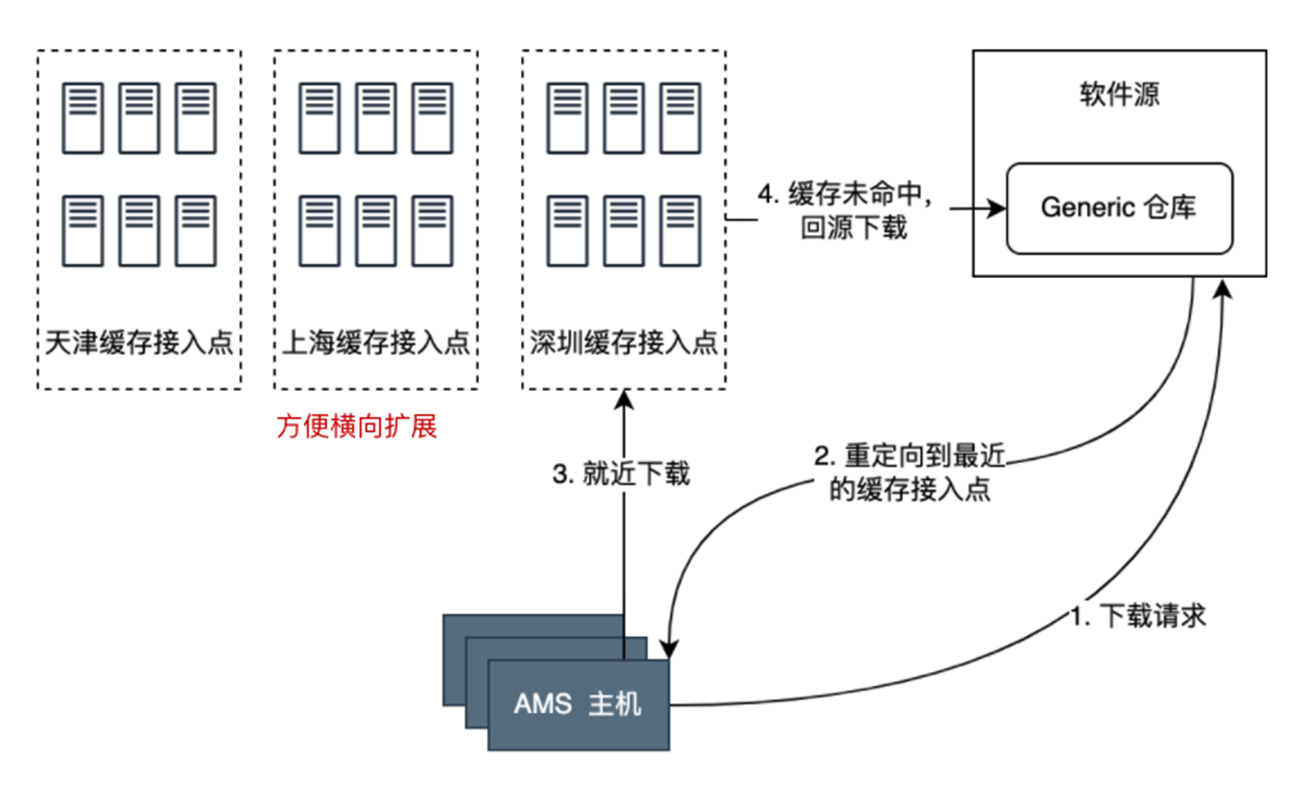
(2)预拉取:由于变更系统知晓发布单的所有行为,所以在任务启动的时候后台就开始比如以200台的并发度去将包往机器上分发。后面执行的机器在单机变更模版上,加一步:判断是否已经分发过。当标志位是已分发时,跳过分发包直接开始变更步骤。(COS使用该方案,节省了缓存接入点,降低带宽与本机器成本)方案上线后,单机执行效率提升40%。
云上2B业务规模量庞大,尤其大客户非常敏感(客户可是将自己的容灾都交给了我们),叠加对象存储COS内部模块数超20个,节点数超10万,对于版本迭代中的质量必须提出极高要求。
经常说的一句话:出一个故障,一周甚至几周都不用干活了。质量对于效率是非直观的,但是始终会影响真实的交付效率。
2019年,某产品原发布系统变更,由于并发度设置不合理,超过线网水位buffer的节点一起变更导致现网过载
2019年,某产品程序变更中由于未经过预发布环境,导致灰度集群能发现的异常被带到了外部云
2020年,某产品原发布系统变更,由于IP填错,导致北京公有云大面积存储设备非预期重启,现网大量失败
2021年,某产品现网程序发布异常触发回退,由于回退功能异常导致二次故障
2022年,某产品变更未考虑混布场景,软件A变更引起机器异常进而导致混部的软件B异常,现网持续失败
......
总的来说:现网发布中,效率是诉求,但发布质量是痛点,若质量问题不解决,单纯提效并不完善。
COS对于发布中引入的质量问题优化是艰难的。年维度的时间迭代,期间包含了COS运营模式改造,存储架构升级,变更体系完善,变更系统适配改造等多项措施。解决质量问题过程中:不仅解决了效率痛点、规范了变更流程、保障变更质量的同时降低变更人力,多方面助力发布提效。下面讲下COS如何对发布质量做提升。
从历史中能看到问题最多的原发布变更系统,就是典型的业务发展初期,考虑的只是变更效率的极致提升,导致管控不足带来的质量风险。所以首先在系统选型上,按照自身业务的管控需求来做。)管控不足主要分为以下六点:

结合COS业务特性进行发布场景梳理与逻辑梳理,分别从正常部署、正常回滚,配置发布,扩缩容,紧急逃生,混部后的发布入手,结合现网变更中遇到的所有问题,确定所有场景。
另外回退对云业务是预案,也就是说当和发布有关联应该第一时间回退,若不是回退问题,其实期望让回滚流转成正向发布以继续变更。

COS对发布前后的观察点梳理,便于理解变更行为从而设置“岗哨”。
配置文件管理升级为配置模板+配置变量的管理模式,对于整体运营上的提升巨大:
(1)固化发布流程
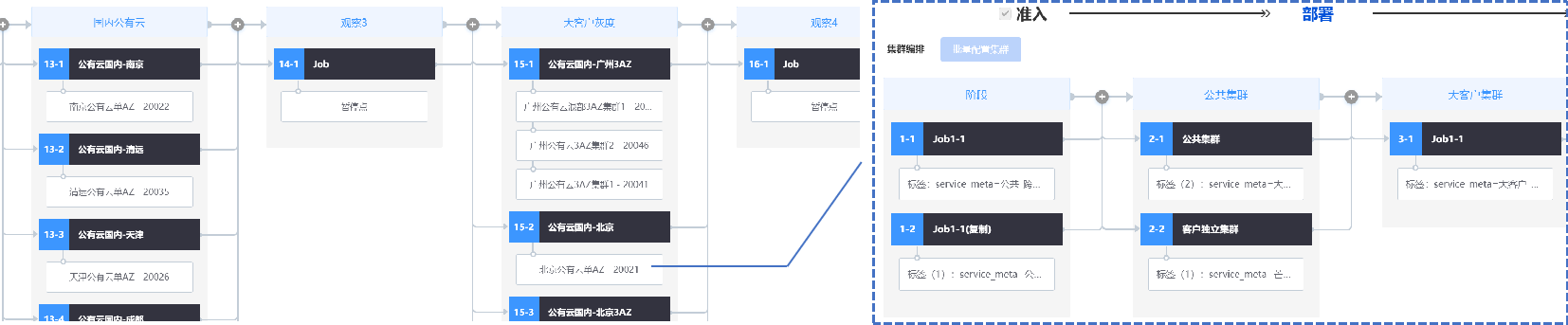
基于站长素材网是通过区域售卖区域管理,COS属于Region级产品,所以按照Region来作为内部发布平台的抽象任务,内部区分实际不同功能特性的集群。但是所有软件的发布方式原本都各式各样,没办法保障每个人来发布都能不出问题。所以我们的方案是,降低发布爆炸半径且固化:区域发布顺序唯一且固化,设置可最大程度降低发布爆炸半径的流程编排并验证(如第二部分COS的直观提效第4点的发布流程优化图),并且所有的规范都通过智研平台标准化落地,一个应用,一个流程,现代化升级和固化发布流程,工具化落地审批、double check、强制回滚,预发布流程等,杜绝人为失误,为自动化变更打好基础。详细的点还包含:
(2)固化发布策略保障了发布流程,当然还要保障发布过程也就是发布策略。失败可暂停,变更必灰度,变更模式统一;

环节 | 现状概述 |
|---|---|
发布规范 | 严格遵循部门->中心->产品内的各项发布规范,规范的重要性不再过多阐述 |
变更日历 | 将变更划分为云上的区域,好处是在变更日历上可以按照区域维度来展示发布,这样能更直观的关联区域变更与区域事件。当前已实现基本的区域变更概念,详细日历落地中(当前可参考coding) |
发布单元 | 区域-集群化部署,屏蔽ip概念,所有变更动作对象都是一个一个的集群或集群组 |
预发布环境 | 既然线上业务越来越重要,那就支付额外成本,搭建一套专用预发布环境给发布用,尽量将明显的版本问题按住在预发布环境,且预发布环境需要构造出现网大部分的场景(曾经出现过发布大客户集群时才出现异常,定位是由于大客户集群有区别于其他集群的场景)。该集群按照现网运营SLA对待,原则上每个模块都要有 |
发布校验 | 部分模块灰度单台阶段引入自动化回归测试或自测能力,保障灰度单台的质量 |
灰度概念 | 变更引入通用部署策略,保障所有变更强制有灰度单台-确认-灰度10%-确认-全量的阶段 |
发布编排 | 全平台统一的发布编排,保障发布集群完整性,发布顺序固定,控制爆炸半径 |
回滚频率 | 版本质量管控比较严格,基本没有回滚 |
double check | 所有操作均有double check审批逻辑,保障每一环节失误率降低 |
版本一致性 | 发布是对全网做一次版本一致性处理,务必覆盖全,既要快,还要稳。由于版本不一致带来的跳版本,不兼容等问题太多,这里不一一列举。 保障 (1)现网版本可统一 (2)校验版本号md5与现网版本md5实时一致,扫描粒度控制5min,保障5min内任何现网程序&配置文件md5改动立即同步,防止违规直接到现网变更 |
发布人力 | 全面外包化,开发提单,运维建设完整规范,外包按流程接手发布,异常运维介入 |
可度量 | 完整变更的各项过程数据、时间数据、行为数据均有记录,通过数据负反馈各个环节调优改进 |
架平很多服务需要极致压榨硬件性能,与存储设备混部。该场景区别于在离线混部,属于在线和在线混部,每个服务都需要保障可用性。故需要考虑发布中此类场景的容灾设计
杜绝(1)软件A数量>>软件B,软件A灰度10%触发机器死机导致软件B100%服务异常 (2)软件B类三副本cell模型(参考索引存储、块存储等实现),软件A机器变更影响B软件成对异常也会导致部分数据不可用的场景
解决方案:引入通用理解的容灾分组,保证上述流程落地后规范并发布

发布问题,解决的要点不仅仅是发布。COS对于变更额外还提出了很多自身运营上的的要求。
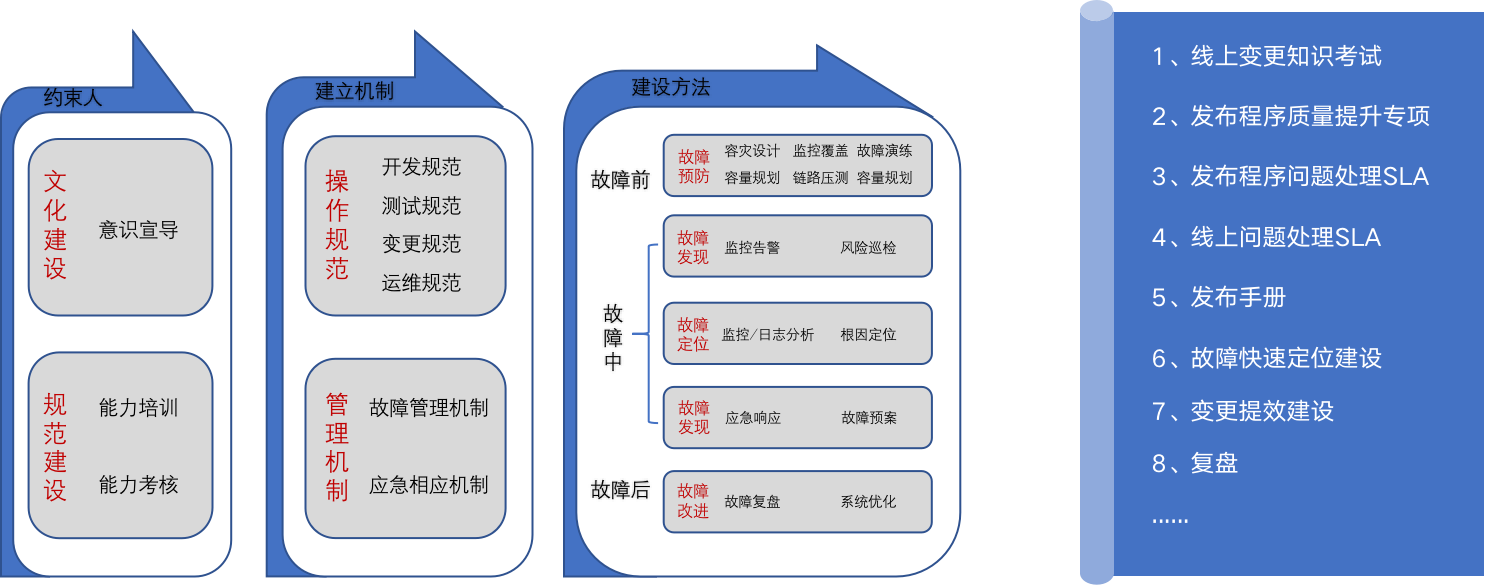
整体来说,从发布概念,发布流程把控的标准化上解决了大部分发布流程上人工误操作可能引起的问题。足够标准化带来的收益就是全面标准化外包化发布,通过运维和开发配合持续降低发布变更的人力投入。并且关键的是:版本发布未再出现由人为操作引起的故障case。

所有发布正向环节如果都考虑完备,能将效率与质量都进行提升,但是否就足够呢?答案肯定是NO,还需要良好的可度量体系才能保障各项环节有数据反馈,持续调优。
一个好的度量一定具有两个特征,一个就是能够回答一个本质问题,另一个是能够引导出正确的行为,两者缺一不可。
目前来看,COS按照每一项发布的目标做行为上的数据审计。可以参考以下几点:

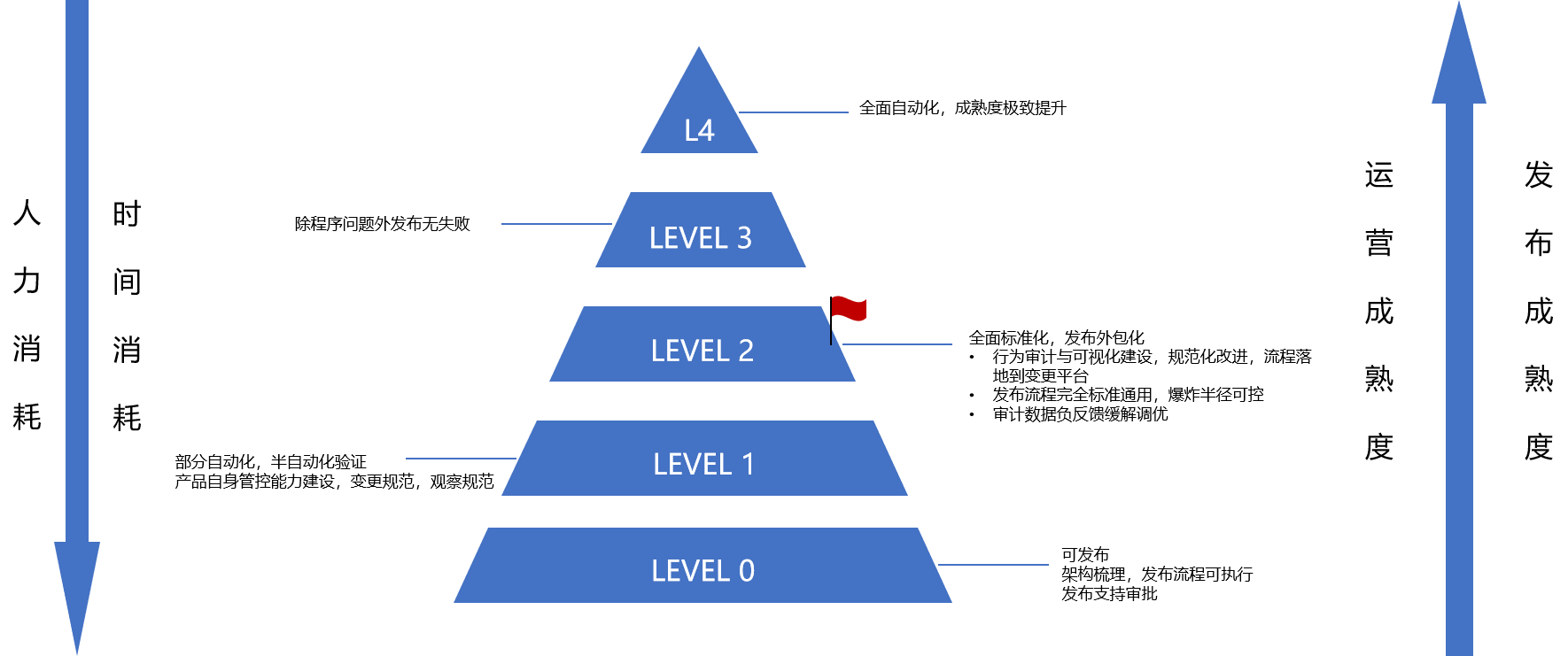
基于站长素材网上发布的理解,COS将发布成熟度区分为以下5级,最终目标为全自动发布。
基于改造升级带来的COS成熟度当前处于 level2,行业领导者如Amazon,Microsoft,Google,Netflix处于level 3 - level 4。
建立标准和成熟度模型,数据化牵引改进发布变更各环节的成熟度,迈向自动化。
这里只是抛砖引玉,期望有更好的变更模式及演进可以交流参考~
- 2020 新架构YottaStore使用新变更系统升级,原生实例管理接口化,加强管控变更
- 2021 COS逻辑层开始更迭变更系统,改造全网应用配置模板统一,使用配置模板+配置变量话改造,区域变更顺序固化,加强流程管控。同步探索效率极致提升
- 2022 全平台实例接口化改造,落地云上逻辑区域发布概念,落地各项变更管控,实现全面标准化&外包化发布
基于主干开发,引入城际快车发布模式,继承其带来的好处:(1)每个人都非常清楚各个时间点 (2)每个人都感觉到特性进展(3)速度不断提升(4)更加聚焦于生产质量。
故事的最后,我们已经足够成熟且有信心应对云上发布的各类问题,下一步就是向全自动化演进。待到COS全自动化发布到来,我们再见。

