

在之前的文章中,我们讲解了索引的基本概念,相信你已经了解了唯一索引和普通索引的区别。今天我们就来讨论一下,在不同的业务场景下,应该选择普通索引,还是唯一索引?
假设你在维护一个市民系统,每个人都有一个唯一的身份证号,而且业务代码已经保证了不会写入两个重复的身份证号。如果市民系统需要根据身份证号查姓名,就会执行下面类似的SQL语句:
select name from user where id_card = 'xxxxxxxxx';所以,你一定会考虑在id_card字段上建索引。
由于身份证号字段比较大,不建议直接把身份证号当做主键,那么现在你有两个选择,要么给id_card字段创建唯一索引,要么创建一个普通索引。如果业务代码已经保证了不会写入重复的身份证号,那么这两个选择逻辑上都是正确的。
现在我要问你的是,从性能的角度考虑,你选择唯一索引还是普通索引呢?选择的依据是什么呢?
简单起见,我们用下面的例子,假设字段k上的值都不重复
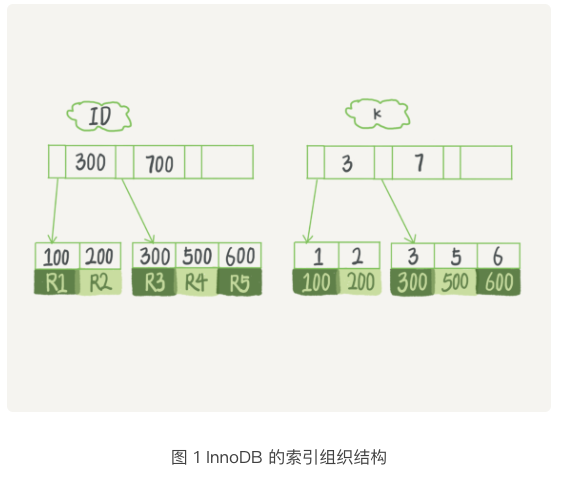
接下来,我们就从这两种索引对查询语句和更新语句的性能影响进行分析。
假设,执行查询的语句是select id from T where k = 5。这个查询语句在索引树上查找的过程,先是通过B+从树根开始,按层搜索到叶子节点,也就是图中右下角的数据页,然后可以认为数据页内部通过二分法来定位记录。
那么,这个不同带来的性能差距会有多少呢?答案是,微乎其微。
你知道,InnoDB的数据是按数据页为单位来读写的。也就是说,当需要读一条记录时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。在InnoDB中,每个数据页的大小默认是16kb。
因为引擎是按页读写的,所以说,当找到k=5的记录的时候,它所在的数据页就都在内存里了。那么对于普通索引来说,要多做一次查找和判断下一条记录的操作,就只需要一次指针寻找和一次计算。
当然,如果k=5这个记录刚好是在这个数据页的最后一个记录,那么要取下一个记录,必须读取下一个数据页,这个操作会稍微复杂一些。
但是我们之前计算过,对于整形字段,一个数据页可以放近千个key,因此出现这种情况的概率会很低。所以我们计算平均性能差异时,仍可以认为这个操作成本对于现在的CPU来说可以忽略不计。
为了说明普通索引和唯一索引对更新语句性能的影响这个问题,我需要先跟你介绍一下change buffer。
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InnoDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
需要说明的事,虽然名字叫做change buffer,实际上它是可以持久化的数据。也就是说,change buffer在内存中有拷贝,也会被写入到磁盘上。
将change buffer中的操作应用到原数据页,得到最新结果的过程成为merge。除了访问这个数据页会触发merge外,系统有后台线程会定期merge。在数据库正常关闭的过程中,也会执行merge操作。
显然,如果能够将更新操作先记录在change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用buffer pool的,所以这种方式还能够避免占用内存,提高内存的利用率。
那么,什么条件下可以使用change buffer呢?
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反了唯一性约束。比如,要插入(4,400)这个记录,就要先判断现在表中是否已经存在k=4的记录,而这必须要将数据页读入内存才能判断。如果都已经读入到内存中,那直接更新内存会更快,就没必要使用change buffer了。
因此,唯一索引的更新就不能使用change buffer,实际上也只有普通索引可以使用。
change buffer用的是buffer pool里的内存,因此不能无限增大。change buffer的大小,可以通过参数innodb_change_buffer_max_size来动态设置。这个参数设置为50的时候,表示change buffer的大小最多只能占用buffer pool的50%。
现在,你已经理解change buffer的机制,那么我们在一起来看看如果要在这个表中插入一个记录(4,400)的话,InnoDB的处理流程是怎么样的。
第一种情况是,这个记录要更新的目标也在内存中。这是,InnoDB的处理流程如下:
这样看来,普通索引和唯一索引对更新语句性能影响的差别,只是一个判断,只会耗费微小的CPU的时间。
但这不是我们关注的重点。
第二种情况是,这个记录要更新的目标页不在内存中。这时,InnoDB的处理流程如下:
将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer因为减少了随机磁盘访问,所以对更新性能的提升会很明显。
之前我就碰到多一件事,有一个DBA的同学跟我反馈说,他负责的某个业务的库内存命中率突然从99%降低到了75%,这个系统处于阻塞状态,更新语句全部堵住。而探究其原因后,我发现这个业务有大量插入数据的操作,而他在前一天把其中的某个普通索引改成了唯一索引。
通过上面的分析,你已经清楚了使用change buffer对更新过程的加速作用,也清楚了change buffer只限于用在普通索引的场景下,而不适用于唯一索引。那么,现在有一个问题就是:普通索引的所有场景,使用change buffer都可以起到加速作用吗?
因为merge的时候真正进行数据更新的时刻,而change buffer的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做merge之前,change buffer记录的变更越多,收益就越大。
因此,对于写多读少的业务来说,页面在写完以后马上被访问的概率比较小,此时change buffer的使用效果最好。这种业务模型常见的就是张丹蕾、日志类的系统。
反过来,假设一个业务的更新模式是写入之后马上就会做查询,那么即使满足了条件,将更新先记录在change buffer,但之后由于马上要访问这个数据页,会立即触发merge过程。这样随机访问IO的次数不会减少,反而增加change buffer的维护成本。所以,对于这中业务模式来说,change buffer反而起到了副作用。
回到我们文章开头的问题,普通索引和唯一索引应该怎么选择,其实,这两类索引在查询能力上没有差别,主要考虑的是对更新性能的影响,所以,我建议你尽量使用普通索引。
如果所有的更新后面,都马上伴随着对这个记录的查询,那么你应该关闭change buffer,而再其他情况下,change buffer都能提升更新性能。
在实际使用中,你会发现,普通索引和change buffer的配合使用,对于数据量大的表的更新优化还是很明显的。
理解了change buffer的原理,你可能会联想到我们在前面的文章中和你介绍过redo log和WAL。
大家很容易混淆redo log和change buffer,下面我们通过一个例子来看一下两者的区别
insert into t(id ,k) values(id1,k1),(id2,k2);这里,我们假设当前k索引树的状态,查到位置后,k所在的数据页在内存中,k2所在的数据页不存在内存中。如图二所示是带change buffer的更新状态图

分析这条更新语句,你会发现它涉及了四个部分:内存,redo log、数据表空间、系统表空间。
这条更新语句做了如下操作:
做完上面这些,事务就可以完成了。所以,你会看到,执行这条更新语句的成本很低,就是写了两处内存,然后写了一处磁盘,而且还是顺序写的。
同时,图中的两个虚线箭头,是后台操作,不影响更新的响应时间。
那在之后的读请求,要怎么处理呢?
比如,我们现在要执行select * from t where k in (k1,k2)。这里,我画了这两个读请求的流程图。
比如读语句在更新语句后不久,内存中的数据都还在,那么此时的这两个读操作就会系统表空间和redo log无关了。所以,我在图中就没画出这两部分。
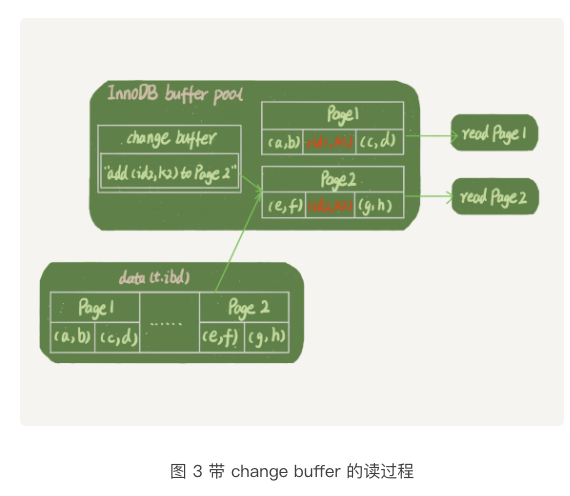
从图中可以看到:
可以看到,直到需要读Page2的时候,这个数据页才会读入内存。
所以,如果要简单的对比两个机制在提升更新性能上的收益的话,redo log主要节省的是随机写磁盘IO的消耗,而change buffer主要节省的则是随机读磁盘的IO消耗。
今天,我们从普通素银和唯一索引的选择开始,分析了数据的查询和更新过程,然后说明了change buffer的机制以及应用场景,最后讲到了索引选择的实践。
由于唯一索引用不上change buffer的优化机制,因此如果业务可以接受,从性能角度出发我建议你优先考虑非唯一索引。
